
ライブラリアン・コラム
コマンドプロンプトを使ってみよう(2)――ファイルの同一性チェック
PDF版ダウンロードページ:https://hdl.handle.net/2344/0002001662
今満 亨崇
2023年4月
はじめに
前稿「コマンドプロンプトを使ってみよう」では、アジア経済研究所図書館(アジ研図書館)が行っている、コマンドプロンプトを使用した業務例を紹介した。今回の記事では、アジ研図書館では未実施だが、将来必要であると筆者が考える「ファイルの同一性チェック」作業について、コマンドプロンプトを用いる例を紹介する。
結論を先に書くと、ファイルの同一性チェックに使用するファイル名とそのハッシュ値の一覧生成には、コマンドプロンプトで下記のコマンドを実行せよ、となる。
for /f %i in ('dir /s /b /a:-D ') do (set /P OUT="%i, "<NUL >> ..\Fname_Hash.txt & CertUtil -hashfile "%i" SHA1 | findstr -V ハッシュ | findstr -V コマンド >> ..\Fname_Hash.txt)
ファイルの同一性チェック(ハッシュ値の計算)
アジ研図書館では、一部の資料を電子化し閲覧に供している。電子化作業は専門業者に委託しており、業者がカメラやスキャナで電子化し、色調補正等の編集を行ったものがマスターファイルとなるが、例えば次のような場面でこのファイル群の完全性が損なわれる(元のファイル群とは別のものとなってしまう)可能性がある。
- マスターファイルの完成から納品するまでの間
納品用メディアの書き込み処理に失敗するなど、開けないファイルが発生することがある。また、意図せぬコピーファイルを作成してしまうこともある。国立国会図書館資料デジタル化の手引き1 でもこれらのチェックの必要性が言及されている。 - 保存用メディアの劣化時
DVD等の物理的な劣化により、開けないファイルが発生する。 - 保存用メディアの媒体変換時
劣化した保存用メディアから、新しい保存用メディアにデータをコピーする時に、元データが読みだせなかったり、書き込み処理に失敗したりして、開けないファイルが発生する。 - ファイル閲覧時
意図せずファイルを削除したり、内容を編集したりしてしまう恐れがある。
膨大に存在する画像データから、このようなデータを目視で発見するのは現実的ではない。そこで、あらかじめファイル名の一覧とそのハッシュ値の対応表を作成しておき、それを機械的に比較する方法を考える。
ハッシュ値とは、ファイルの内容から機械的に計算される値である。元のファイルと改変されたファイルが同一のハッシュ値を持つことはほぼありえない。図書館や出版関係者であれば、ISBNのチェックデジットのようなものであると思ってもらえればよいだろう。ISBNの末尾1桁も、他の桁の値から計算して算出されるもの2であり、例えば書籍検索システムにおいては入力ミスの判定に役立っている。
説明用ファイルの確認
では、コマンドを紹介していこう。最終的に実行するコマンドは「はじめに」で示したとおりだが、本記事ではそのコマンドを分解し、続く項で順を追って解説していく。
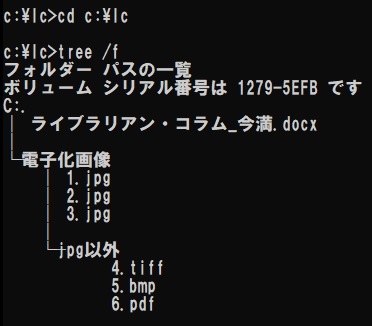
さて筆者は今回の記事のために、Cドライブの直下に“lc”というフォルダを用意した。その中の構成は図1のようになっている。本記事の下書きであるwordファイルのほか、“電子化画像”というフォルダがありその中には3つのjpgファイル(1.jpg, 2.jpg, 3.jpg)と“jpg以外”というフォルダが存在している。さらに“jpg以外”というフォルダの中には3ファイル(4.tiff, 5.bmp, 6.pdf)が存在している。
1ファイルのハッシュ値計算と書き出し
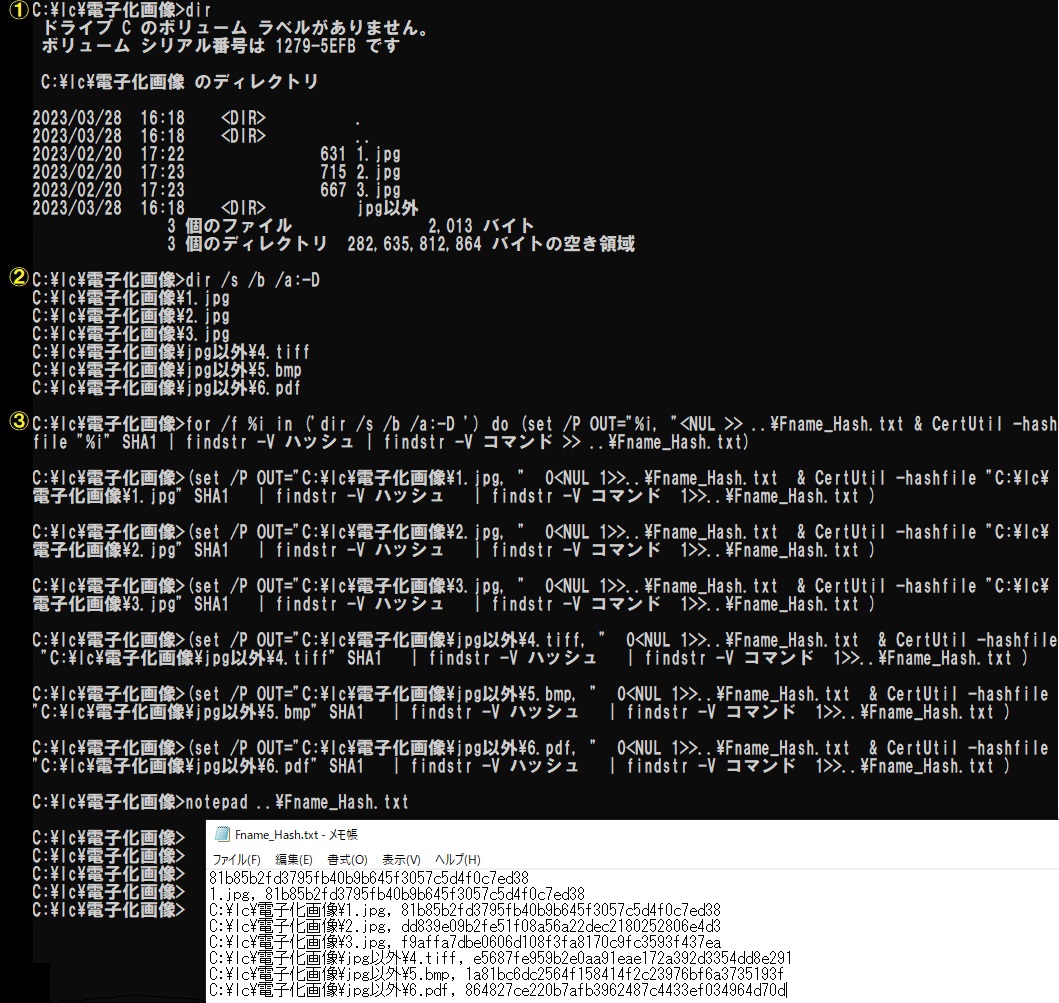
ハッシュ値はCertUtilコマンドにより求めることができる。図2を見ながら具体的に説明していこう。まずは1ファイルのハッシュ値をテキストファイルに書き出すことを目標とする。
 ②CertUtil -hashfile 1.jpg SHA1 (改行) ③CertUtil -hashfile 1.jpg SHA1 | findstr -V ハッシュ | findstr -V コマンド (改行) ④CertUtil -hashfile 1.jpg SHA1 | findstr -V ハッシュ | findstr -V コマンド >> ..\Fname_Hash.txt (改行) ⑤notepad ..\Fname_Hash.txt")
①ではcdコマンドを用いて“c:\lc\電子化画像”フォルダへ移動している。このフォルダ内にある“1.jpg”に対して、②ではCertUtilコマンドを実行しハッシュ値を求めている。このコマンドを分解すると次のようになる。
- CertUtil: 証明書関係の処理を行うコマンド。オプションにより具体的に実行する機能を決定する。
- -hashfile "ファイル名": 指定されたファイルのハッシュ値を計算するオプション。
- SHA1: ハッシュ値の計算にSHA1という方式を用いる。この他、SHA256、MD5、等の方式も存在する。
さて②の実行結果を見てみると、2行目に乱数のように見える英数字(81b85b2fd~)が表示されている。これが“1.jpg”のハッシュ値である。一方、1行目(SHA1 ハッシュ~)や、3行目(~コマンドは正常に完了しました)は不要な情報であるので、これを出力しないように③ではfindstrコマンドを2回追加している。1回目は“ハッシュ”の文字を含む行を除外し、2回目は“コマンド”の文字を含む行を除外する処理である。findstrコマンドは文字列を検索するコマンドで、詳細は次のとおりである。
- |: パイプ(パイプライン)と呼ばれる記号。この記号の左側の実行結果を元に、この記号の右側の処理を実行する。これ自体はfindstrコマンドとは関係なく、多くの場面で用いることができる。
- findstr: 文字列を検索し一致する行を出力するコマンド。
- -V 単語: 単語に一致しない行を検索にマッチさせるオプション。
最後に、この処理の結果をファイルに出力しよう。それが④であり、“ >> ファイル名”を③の末尾に追記することで実現している(ファイル名は任意。ここではFname_Hash.txt)。“ファイル名”の冒頭部分に“..\”と書いているが、これは1つ上の階層であることを示す。つまり、このコマンドを実行しているのは“c:\lc\電子化画像”の階層だが、Fname_Hash.txtが保存されるのは“c:\lc”の階層となるようにしている。これは後の処理で生じるエラーを回避するためである。実際にハッシュ値が書き込まれているかどうかはFname_Hash.txtを開いてみれば確認できる。マウスでアイコンをダブルクリックしてもよいが、せっかくコマンドプロンプトを使用しているので、“notepad ファイル名”と入力・実行すればメモ帳が起動する(⑤)。
ファイル名の追加出力とcsv形式のデータ生成
ここまでハッシュ値を計算してファイル出力できるようにしてきたが、実利用を想定して、ファイル名をカンマ区切りで併記してみよう。つまり一行が”ファイル名, ハッシュ値”のcsv形式のデータを作成するのである。図3を見ながら説明する。
 ②set /P OUT=\"1.jpg, \"<NUL (改行) ③set /P OUT=\"1.jpg, \"<NUL >> ..\Fname_Hash.txt & CertUtil -hashfile \"1.jpg\" SHA1 | findstr -V ハッシュ | findstr -V コマンド >> ..\Fname_Hash.txt (改行) ④notepad ..\Fname_Hash.txt")
まずは①②の実行結果を見比べていただきたい。いずれもコマンドの実行結果として任意の文字を出力できるコマンドである。文字列出力に通常は①のechoコマンドを使用するが、このコマンドでは改行が無駄に出力されてしまう。そこで今回は②を採用する。本来の用途と異なる使い方をしているので解説は避けるが、“1.jpg,”の部分を書き換えれば、任意の文字列をコマンドの実行結果として出力できるようになる。
③では、②の実行結果および図2で説明してきたハッシュ値の出力を“..\Fname_Hash.txt”へ書き込んでいる。コマンドの区切りに“&”の記号を用いているが、これは“&”の左側の処理が終わったら、右側の処理を実行するための記号である。“|(パイプ)”のように左側の結果を引き継ぐことはしない。④ではメモ帳を開いて実行結果を確認しており、確かに“ファイル名, ハッシュ値”のcsv形式のデータが出力されていることが確認できる。
複数ファイルの一括処理
最後に、フォルダ内のすべてのファイルを対象に、ファイル名とハッシュ値の一覧を作成しよう。ここからは図4を参照する。
フォルダ内のファイル表示にはdirコマンドを用いるが、①の実行結果を見ると分かるとおり、ファイル名以外の不要な情報(日時やファイルサイズ)も表示されている。また、より下の階層にあるファイル(“jpg以外”のフォルダの中身)は表示されない状態である。
そこで②のようにオプションを付与し、ファイル名の絶対パスのみの一覧を取得する。これにより処理すべき対象ファイルの一覧を作成することができる。コマンドとオプションの説明は次のとおりである。
- dir: 指定した階層のファイル、フォルダの一覧を表示するコマンド。通常はコマンドを実行した階層が指定される。
- /s: より下の階層のファイル、フォルダを全て表示するオプション。
- /b: ファイル、フォルダの名前のみを表示するオプション。/sオプションと組み合わせることでc:\からの絶対パスでの表示となる。
- /a:-D: フォルダを表示対象から除外するオプション。
③では、“for ~ in ~ do”のコマンドを用いてすべてのファイルに対する処理を実行させている。前半の[for /f %i in ('dir /s /b /a:-D ')]の部分は、まず前述のとおり dirコマンドでファイルの一覧を作成している。その結果を1行ずつ%iという変数に代入し、続く処理で利用する準備をしている。
後半の[do (set /P OUT="%i, "<NUL >> ..\Fname_Hash.txt & CertUtil -hashfile "%i" SHA1 | findstr -V ハッシュ | findstr -V コマンド >> ..\Fname_Hash.txt)]では、図3を用いて説明したハッシュ値の計算とファイル出力のためのコマンドがほぼそのまま記載されている。違う点は画像ファイル名を記していた部分が“%i”と変数になっている。前段落で説明したとおり“%i”にはファイル名が順番に代入されるため、これを用いてすべてのファイルに対する処理を実現しているのである。③のコマンドに続く行を見ると処理が実行されている様子が見て取れるだろう(これらの行はシステムが勝手に表示するものであり、人が入力・実行したものではない)。for~doの部分がなくなっており、また、“%i”の部分が実際のファイル名(ファイルパス)に変換されている。最後にテキストファイルを開いてみれば確かに実行結果が出力されている。
for ~ in ~ doの代替方法
さてここまでコマンドの説明をしてきたが、特にfor~in~doの部分は理解が難しいのではないだろうか。そこで、代替手段としてExcelを用いてコマンドを作成する方法を紹介する。要は、図3③のコマンドの中で、ファイル名に相当する部分だけ書き換えたものを、全対象ファイル分用意すればよいのである。
本項の説明の前提として、図3③のコマンドが動作するところまでは完了しているものとする。その後、対象とするファイルの一覧を作成する。それが図5①であり、dirコマンドを前述のとおり使用し、list.txtというファイルを作成している。ファイルの書き出しには“>>”ではなく“>”を使用している。“>>”は元のファイルの内容に追記する命令だが、“>”は元ファイルの内容をすべて消して今回の実行結果を上書きする命令である。どちらを用いても間違いではないので、用途に合う方を選択しよう。
さて、処理対象とするファイルの一覧を作成したら、それをメモ帳で開きコピーして(②)、Excelに貼り付けよう(③)。図5中では、B列およびD列に②を貼り付けている。では、A列、C列、E列に何を入力しているかというと、コマンドの残りの部分である。図5では見切れている部分もあるので、下記に改めて示す。
- A列: set /P OUT="
- C列: , "<NUL >> ..\Fname_Hash.txt & CertUtil -hashfile "
- E列: " SHA1 | findstr -V ハッシュ | findstr -V コマンド >> ..\Fname_Hash.txt
最後にF1セルに”=A2&B2&C2&D2&E2”と、A-E列の文字列をつなげる数式を入力すれば、1行分のコマンドが完成する。F1セルをコピーして、F2以下のセルに貼り付けすれば、すべてのファイルに対するコマンドが完成する。
コマンドが完成したら、F列に生成されたコマンド全体を選択、コピーして、そのままコマンドプロンプト上で貼り付け(右クリック1回)すると、上から順に処理が実行される。図4③のように次々とコマンドが実行されるはずだ。
 ②notepad ..\list.txt")
今回作成したファイルの活用方法例
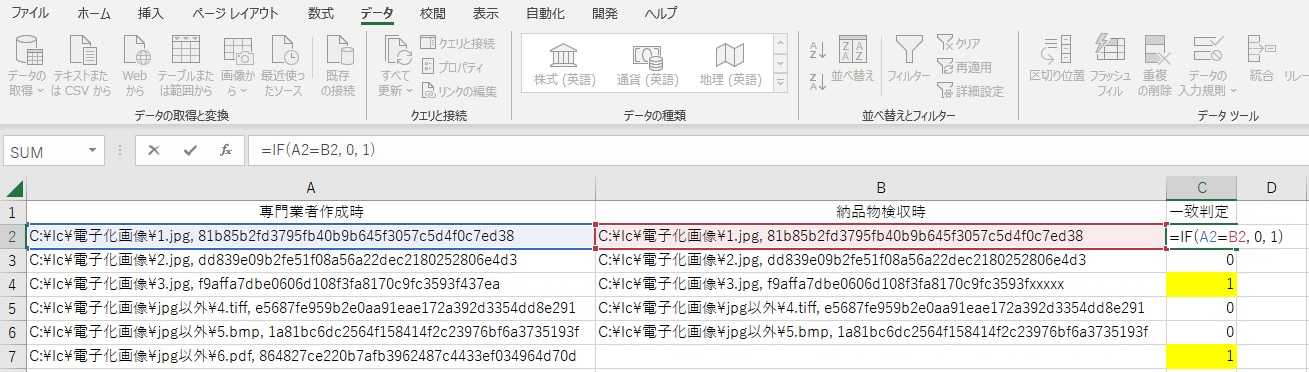
本記事の冒頭で「マスターファイルの完成から納品するまでの間」にデータが壊れる可能性があることを示した。ではこのようなケースをサンプルとして問題のあるデータの発見方法を示す。といってもやることは単純で、マスターデータの完成時点と、それが納品された時点で、今回紹介したコマンドを用いてファイル名とハッシュ値の一覧をそれぞれ作成し、Excelで比較すればよい。
ハッシュ値のデータはファイル名とのカンマ区切り(csv形式)で作成したが、納品されたファイルの抜けや破損データの有無を確認するだけであれば、Excel上でこれをわざわざ分離する必要はない。メモ帳のデータをすべて選択(Ctrl+A)し、コピーしてExcelに貼り付けたものをそのまま比較用のデータにできる。
例えばA列に業者が作成したデータ、B列に図書館側で作成したデータを貼り付け、C列でif文を用いて一致を判定すれば、問題のあるファイルがすぐにわかる。図6では4行目のデータはハッシュ値の不一致、7行目のデータはファイルの抜けを発見している。
実際の確認作業時には、各データの並び順を統一するためにあらかじめソートしたり、ファイル名とハッシュ値のセルを分離したりするなどして、より詳細な準備や調査が必要だと思われるが、Excelの使い方の説明になってしまうので本稿では割愛する。
おわりに
国立国会図書館資料デジタル化の手引き1では 「4 画像データの品質検査」の1項目として「4.6ファイルの同一性チェック」が挙げられており、チェックサム(=ハッシュ値)を用いる方法とCompコマンドを使用する方法に言及されている。ただ、「こういった手段が存在する」程度の記述であり、それぞれの具体的な方法までは記されていない。本稿はチェックサム(=ハッシュ値)を用いる方法について、作業手順として具体化したものである。なお、Compコマンドは大量のデータを一括比較するには向かないと考え、作業手順化する検討はしていない。
電子ファイルの保存管理には、紙の資料とは異なる難しさが存在する。本記事がデジタル化した資料を適切な状態で永く保存し続けるための一助となれば幸いである。
注
- 国立国会図書館関西館電子図書館課『国立国会図書館資料デジタル化の手引2017年版』 国立国会図書館, 2017, p.43-54, https://dl.ndl.go.jp/view/download/digidepo_10341525_po_digitalguide170428.pdf?contentNo=1, (参照 2023-03-30).
- 日本図書コード管理センターマネジメント委員会ワーキンググループ「第三部 ISBN/日本図書コードの作り方とルール」『ISBNコード/日本図書コード/書籍JANコード利用の手引き ホームページ版(2019年1月改訂版)』日本図書コード管理センター, 2019, p.11-17, https://isbn.jpo.or.jp/doc/08.pdf, (参照 2023-03-30).
著者プロフィール
今満亨崇(いまみつみちたか) アジア経済研究所学術情報センター図書館情報課。担当は図書館の管理するシステム全般。最近の活動に日本図書館協議会開催の研修講師 や「特集:インフォプロのためのプログラミング事例集 」(『情報の科学と技術』70巻4号、2020年)の編集担当主査などがある。